
Understanding ETL Pipelines: Extract, Transform, and Load
Master the essentials of data loading in ETL pipelines and optimize your process with effective techniques and tools.
Businesses rely heavily on data to drive decisions and gain valuable insights. However, data often exists in various formats and sources, making it challenging to process and analyze efficiently. This is where ETL (Extract, Transform, Load) pipelines come into play. ETL pipelines provide a systematic approach to extract data from multiple sources, transform it into a desired format, and load it into a target destination. In this blog post, we will explore the fundamentals of ETL pipelines, discuss their importance, and see some examples using Python.
- What is an ETL Pipeline?
- The Role of ETL Pipelines in Data Processing
- Extracting Data from API Endpoints
- Transforming Data for Insights
- Loading Data into a Target Destination
- Data Quality and Monitoring
Before we dive into the details of each section, let's understand the scenario that inspired this blog post.😛
Recently, as part of an interview process for a new position🙄, I was given a task to complete. The task involved creating an ETL client in Python that would extract, transform, and load information from an API endpoint. To optimize performance, I decided to utilize threadpooling, allowing each request, along with the transformation and load methods, to be executed in separate threads. This hands-on experience not only allowed me to complete the task but also provided me with invaluable insights and a wealth of new knowledge in the field.
Now, let's explore each section in detail and gain a comprehensive understanding of ETL pipelines and their implementation.
What is an ETL Pipeline?

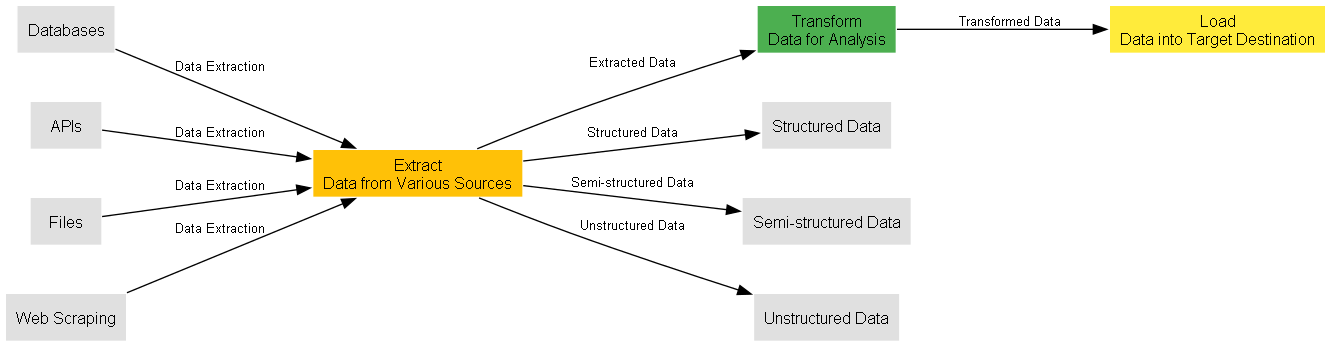
An ETL pipeline is a data integration process that involves three fundamental steps: Extract, Transform, and Load. Each step plays a crucial role in managing and processing data efficiently. Let's explore each step in detail:
Extract
The first step in an ETL pipeline is extracting data from various sources such as databases, APIs, files, or web scraping. The extraction process involves fetching the required data from the source systems and making it available for further processing. The extracted data could be structured, semi-structured, or unstructured, depending on the source.
Let's say you want to extract data from a Postgres Database using SQLAlchemy in Python:
from sqlalchemy import create_engine
import pandas as pd
# Create a database connection
engine = create_engine('postgresql://username:password@localhost:5432/database')
# Execute SQL query and extract data into a pandas DataFrame
query = "SELECT customer_name, order_id, order_date, product, quantity FROM orders"
df = pd.read_sql_query(query, engine)Transform
Once the data is extracted, it often requires transformation to make it suitable for analysis or storage in a target system. Transformation involves cleaning, filtering, aggregating, and restructuring the data. This step ensures that the data is in a consistent format and meets the desired quality standards.
Let's say the extracted data contains inconsistent date formats and duplicate entries. To transform the data, you can use Python libraries like pandas to perform operations such as data type conversions, deduplication, and date formatting.
# Convert date column to a standardized format
df['order_date'] = pd.to_datetime(df['order_date'], format='%Y-%m-%d')
# Remove duplicate entries
df.drop_duplicates(inplace=True)Load
After the data is extracted and transformed, it needs to be loaded into a target destination such as a data warehouse, database, or analytics platform. The load step involves storing the processed data in a structured manner to enable easy access and analysis.

Let's assume you want to load the transformed data into a PostgreSQL database table. You can use Python libraries like SQLAlchemy to establish a connection and insert the data into the table.
# Create a database connection
engine = create_engine('postgresql://username:password@localhost:5432/database')
# Load the transformed data into a table
df.to_sql('processed_orders', engine, if_exists='replace', index=False)Understanding the basics of ETL pipelines and the importance of each step sets the foundation for efficient data processing. Now, let's continue to explore the extraction of data from API endpoints, data transformation techniques, and the loading of data into target destinations.
The Role of ETL Pipelines in Data Processing
ETL pipelines play a crucial role in managing and processing data effectively. They serve as the backbone of data integration and enable organizations to extract valuable insights from diverse data sources. Here are some key roles of ETL pipelines:
- Bring data together: ETL pipelines collect data from different sources and put it in one place, like a data warehouse or data lake.
- Improve data quality: ETL pipelines make sure that the data is good by cleaning it up, making it consistent, and checking for errors.
- Change data to be useful: ETL pipelines transform the data into a format that can be analyzed and reported on.
- Add more information: ETL pipelines can make the data better by adding more details from other sources.
- Follow rules and keep data safe: ETL pipelines make sure that data is handled properly and follows rules for privacy and security.
- Handle lots of data: ETL pipelines are built to handle big amounts of data. They can process it quickly and efficiently, even when there is a lot of it.
- Automate and schedule tasks: ETL pipelines can be set up to run on their own at specific times or in response to certain events.
ETL pipelines enable organizations to extract valuable insights, make informed decisions, and gain a competitive advantage in the data-driven landscape.
Extracting Data from API Endpoints
APIs provide a convenient way to extract data from remote systems or services. ETL pipelines can leverage APIs to retrieve data and incorporate it into the data processing flow. In this section, we will explore how to extract data from API endpoints and incorporate it into an ETL pipeline.

- Understanding API Endpoints:
API endpoints are specific URLs or routes provided by an API that allow you to access and interact with its resources. Each endpoint represents a specific data source or functionality exposed by the API. To extract data from an API, you need to identify the relevant endpoint and understand the data it provides. - Making API Requests:
To retrieve data from an API endpoint, you typically use HTTP methods such as GET, POST, PUT, or DELETE. The choice of method depends on the API's design and the type of operation you want to perform. GET requests are commonly used for retrieving data. - Handling Authentication:
Some APIs require authentication to access their data. This can involve using API keys, access tokens, or other authentication mechanisms. Make sure to understand the authentication requirements of the API you are working with and include the necessary authentication parameters in your requests. - Parsing API Responses:
APIs usually return data in a structured format such as JSON or XML. After making an API request, you need to parse the response to extract the relevant data that you wish to incorporate into your ETL pipeline.
Let's consider an example where we want to extract data from a hypothetical weather API that provides weather information for different locations. The API endpoint we are interested in is https://api.example.com/weather.
import requests
import json
# Make a GET request to the weather API endpoint
response = requests.get('https://api.example.com/weather')
# Check the response status code
if response.status_code == 200:
# Parse the JSON response
data = response.json()
# Extract relevant data from the response
temperature = data['temperature']
humidity = data['humidity']
# Perform further processing with the extracted data
# (e.g., transform and load into a target destination)
...
else:
print('Failed to retrieve weather data. Status code:', response.status_code)In the above example, we use the requests library in Python to make a GET request to the weather API endpoint. We check the response status code to ensure the request was successful (status code 200). If successful, we parse the JSON response using the json module and extract the desired data, such as temperature and humidity.
Transforming Data for Insights
Data transformation is a crucial step in the ETL pipeline that involves manipulating, cleaning, and structuring the extracted data to make it suitable for analysis and gaining valuable insights. In this section, we will explore various data transformation techniques that can be applied to the extracted data.
Cleaning and Filtering
Data cleaning involves removing or correcting inconsistent, inaccurate, or incomplete data. This may include handling missing values, removing duplicate records, and standardizing data formats. Filtering allows you to focus on specific subsets of data based on certain criteria.
Suppose you have extracted customer data that contains missing values and duplicate entries. You can perform the following transformation tasks:
# Dropping duplicate records
df.drop_duplicates(inplace=True)
# Handling missing values
df.fillna(0, inplace=True)
# Applying data filters
filtered_df = df[df['age'] > 18]Data Type Conversion
Data extracted from different sources may have varying data types. Data type conversion transforms the data into a consistent format. This step ensures that the data can be properly interpreted and analyzed.
If you have a column containing dates as strings in the format 'YYYY-MM-DD', you can convert it to the datetime data type for easier manipulation and analysis.
# Converting date column to datetime data type
df['date'] = pd.to_datetime(df['date'], format='%Y-%m-%d')Aggregation and Summarization:
Aggregation involves combining multiple data points into a single value. Summarization techniques such as grouping, counting, averaging, or calculating sums can provide valuable insights by condensing the data.
Suppose you have extracted sales data with individual transactions. You can aggregate the data to obtain total sales by product category.
# Aggregating sales data by product category
sales_by_category = df.groupby('category')['sales'].sum()Joining and Merging
Joining or merging data involves combining multiple datasets based on common attributes or keys. This allows you to enrich your data with additional information or consolidate related data from different sources.
If you have extracted customer orders and customer information from separate sources, you can join the datasets based on a common customer ID to create a unified view.
# Joining customer order data and customer information
merged_df = pd.merge(order_data, customer_info, on='customer_id')Data Enrichment
Data enrichment involves enhancing the existing data with additional information from external sources. This can help provide a more comprehensive view of the data.
Suppose you have extracted product data that includes product names and categories. You can enrich the data by retrieving additional information such as product descriptions or customer ratings from an external source.
# Enriching product data with additional information
product_data['description'] = external_api.get_product_description(product_data['product_id'])By applying these transformation techniques, you can prepare the extracted data for analysis, reporting, or loading into a target destination.
Loading Data into a Target Destination
Once the data has been extracted from various sources and transformed for analysis, the next step in the ETL pipeline is to load the data into a target destination. The target destination is typically a data warehouse, or a database where the data will be stored and made available for querying and analysis. In this section, we will explore the process of loading data into a target destination.
Data Modeling
Before loading the data, it's important to design an appropriate data model for the target destination. The data model determines the structure, relationships, and organization of the data in the destination.
Choosing a Loading Mechanism
There are various loading mechanisms available, depending on the target destination and the specific requirements of the data pipeline. Common loading mechanisms include:
- Batch Loading: In batch loading, data is loaded in bulk at scheduled intervals or when a significant amount of new data is available. This is suitable for scenarios where real-time data is not a requirement.
- Stream Loading: Stream loading involves continuously loading data in real-time or near-real-time as it becomes available. This is useful for applications that require up-to-date data for immediate analysis or decision-making.
- Incremental Loading: Incremental loading involves loading only the new or modified data since the last load. This minimizes the processing time and resource utilization when dealing with large datasets.
- Upsert Loading: Upsert loading combines the functionalities of insertion and updating. It inserts new records and updates existing records in the target destination based on a defined key or condition.
Data Loading Tools and Technologies
There are several tools and technologies available to facilitate the data loading process. These include:
- ETL Tools: ETL tools have user-friendly interfaces or scripts that help define and automate the data loading process. They can connect to different data sources and destinations and handle data transformation and loading tasks.
- Data Integration Platforms: These platforms offer complete solutions for extracting, transforming, and loading data. They can handle complex data integration scenarios and manage the entire pipeline from start to finish.
- Database-specific Tools: Some databases have their own tools and utilities for loading data. These tools are specifically designed for their respective database systems.
Data Loading Best Practices
To ensure a successful data loading process, it's important to follow best practices:
- Data Validation: Check the data as it's being loaded to make sure it's accurate, consistent, and complete.
- Logging and Monitoring: Keep track of the data loading process by recording important information and watching for errors or unusual things.
- Data Partitioning and Indexing: Organize the data in a way that makes it easier to find and retrieve.
- Error Handling and Retry: Handle any problems or failures that happen during the data loading process.
- Scalability and Performance: Design the data loading process to handle larger amounts of data and make it work faster. Use techniques like doing things in parallel, optimizing the size of batches, and allocating resources effectively.
Data Quality and Monitoring
Maintaining data quality and monitoring the ETL pipeline are essential aspects of ensuring accurate and reliable data for analysis. In this section, we will explore the importance of data quality and monitoring in the ETL process and discuss best practices.
Data Quality
Data quality refers to the accuracy, completeness, consistency, and reliability of the data. Poor data quality can lead to incorrect analysis, flawed insights, and unreliable decision-making. It is crucial to implement measures to ensure data quality throughout the ETL pipeline.
- Data Profiling: Analyze the data to check for problems like missing values, mistakes, and inconsistencies.
- Data Cleansing: Fix the data issues by removing duplicates, filling in missing values, and making sure the data follows the same format.
- Data Validation: Check that the data is correct and reliable by comparing it to rules and making sure it fits the expected patterns.
- Data Quality Metrics: Set up measurements to track how good the data is over time, including things like how complete, accurate, timely, and consistent it is.
Data Lineage
Data lineage refers to the ability to trace the origin, movement, and transformation of data throughout the ETL pipeline. It provides visibility into how data flows from source systems to the target destination and helps ensure data integrity and compliance.
- Capture Metadata: Save information about where the data comes from, what changes it goes through, and where it ends up.
- Impact Analysis: Study the potential effects of changes or problems in the ETL pipeline.
Data Monitoring
Monitoring the ETL pipeline helps identify issues, bottlenecks, and anomalies in real-time or near-real-time. It allows you to proactively address problems and ensure the smooth operation of the pipeline.
- Automated Alerts: Configure automated alerts and notifications to be triggered when specific events or conditions occur, such as data quality issues, failed data loads, or performance degradation.
- Performance Monitoring: Monitor the performance of the ETL processes, including data extraction, transformation, and loading.
- Error Handling and Logging: Implement comprehensive error handling and logging mechanisms to capture and log errors, exceptions, and warnings that occur during the ETL process.
Regular Audits and Reviews
Conduct regular audits and reviews of the ETL pipeline to ensure compliance, adherence to best practices, and continuous improvement. This includes reviewing data quality, validating transformations, and assessing the effectiveness of monitoring mechanisms.
By prioritizing data quality and implementing monitoring practices, you can maintain the reliability and accuracy of your data, leading to better decision-making and improved business outcomes.
Conclusion
The ETL process plays a crucial role in collecting, transforming, and loading data from various sources into a target destination for analysis and decision-making. It involves extracting data from disparate sources, applying transformations to ensure data consistency and integrity, and loading the transformed data into a target destination.
Throughout this tutorial, we have explored the considerations involved in the ETL process. We discussed the importance of data extraction techniques, including querying databases, utilizing APIs, and working with flat files. We also delved into the significance of data transformation, covering tasks such as data cleansing, aggregation, enrichment, and merging.